



DeepSeek開源周正式拉開帷幕,為AI社區帶來了一系列開源代碼庫,北京時間周一上午九點,DeepSeek公布了開源周的第一個項目:FlashMLA;發布后,FlashMLA迅速成為全球開發者關注的焦點,在GitHub上的Star數已突破5000。
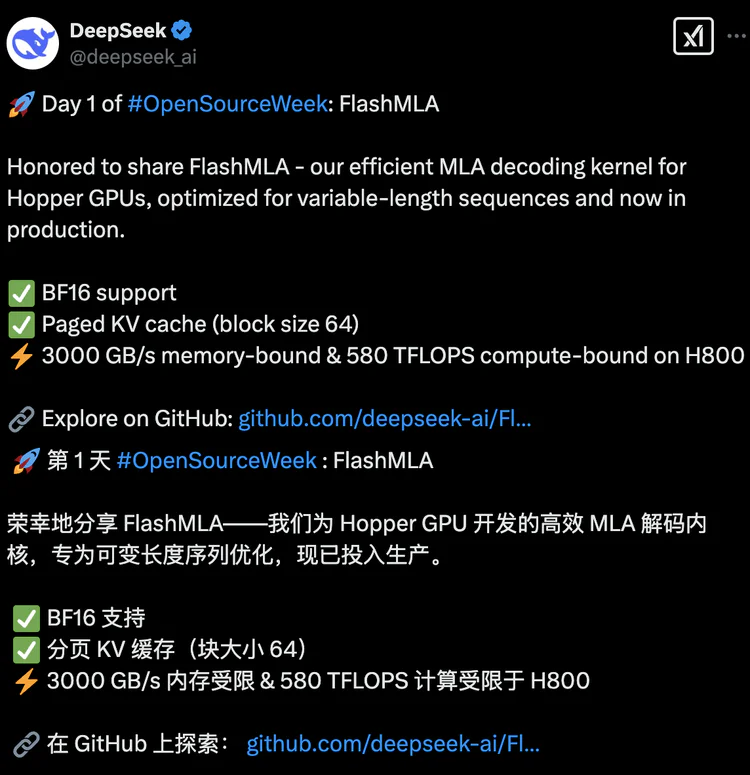
FlashMLA是DeepSeek專為英偉達HopperGPU設計的高效MLA(Multi-Head LatentAttention)解碼內核,用于優化可變長度序列的推理服務,其目標是在H100等Hopper GPU上實現更快的推理速度,且所有代碼均經過實際業務場景驗證,目前正處于持續發布中。
一、FlashMLA的核心價值與技術亮點
1. 解決變長序列處理痛點
傳統方法在處理不同長度的輸入序列(如用戶評論、對話文本)時,存在靜態填充(Padding)導致的算力浪費或截斷造成的信息丟失問題。FlashMLA通過**分頁鍵值緩存(Paged KV Cache)**和動態內存分配機制,實現了顯存資源的智能調度,類比“智能分揀系統”,顯著提升GPU利用率1510。
2. 技術創新與性能突破
BF16混合精度支持:兼顧計算效率與精度,適應大模型的高性能需求。
分塊調度與異步內存預取:塊大小為64的分頁KV緩存技術,結合類操作系統的虛擬內存管理,釋放Hopper GPU的Tensor Core潛力。
極致性能指標:在H800 GPU上,顯存帶寬達3000 GB/s(內存受限場景),算力峰值達580 TFLOPS(計算受限場景),接近硬件理論極限。
二、實際應用與開源意義
1. 生產環境驗證與成本優化
FlashMLA已在DeepSeek的生產環境中應用,通過動態資源分配減少GPU服務器需求,直接降低推理成本。例如,長上下文對話場景的推理速度提升顯著,為大模型商業化落地提供支持。
2. 推動AI開源生態
開源首日,FlashMLA的GitHub倉庫即獲1700星,吸引全球開發者關注。馬斯克旗下xAI的大模型Grok3評價其為“渦輪增壓引擎”,認為其性能可媲美FlashAttention等頂尖方案410。DeepSeek此舉也被視為對OpenAI封閉策略的挑戰,網友稱其“以開放共贏定義AI未來”。
三、安裝要求與快速上手
? 運行環境:需Hopper架構GPU(如H800)、CUDA 12.3+、PyTorch 2.0+16。
? 安裝與測試:通過python setup.py install安裝,運行python tests/test_flash_mla.py進行基準測試24。
四、行業影響與后續展望
1. 開源周后續計劃
DeepSeek將在2月24日至28日陸續開源4個代碼庫,內容可能涉及AI算法優化、模型輕量化等,甚至被猜測包含AGI相關技術。
2. 行業趨勢推動
開源已成為AI領域的新趨勢,國內頭部廠商如阿里、百度也加速布局。例如,阿里通義千問系列衍生模型數已超Meta的Llama,成為全球最大開源模型系列。
FlashMLA的發布不僅是技術突破,更是DeepSeek推動開放生態的里程碑。其通過硬件級優化與開源共享,為AI開發者提供了高效工具,同時為行業樹立了“透明化技術探索”的標桿。后續項目的開源值得期待,或將進一步重塑AI技術發展的格局。


